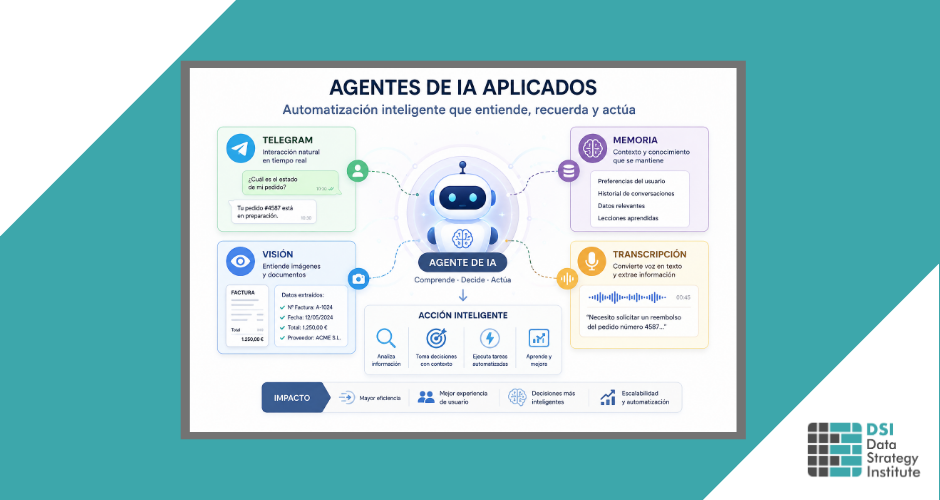
Diseñar un agente conversacional con IA no consiste únicamente en conectar un bot a un modelo de lenguaje. Para que el sistema funcione de forma útil, cada tipo de entrada debe recibir el tratamiento adecuado antes de generar una respuesta.
Texto, voz e imagen no viajan igual, no se procesan igual y no pueden entregarse sin preparación al mismo nodo de inteligencia artificial. La clave está en construir un workflow capaz de leer el dato correcto, dirigirlo por la ruta adecuada y devolver una respuesta común al usuario.
Un agente conectado a Telegram puede recibir mensajes escritos, notas de voz o imágenes. Aunque para el usuario todo ocurre dentro de una misma conversación, técnicamente cada entrada requiere una lógica diferente.
El texto puede normalizarse y pasar directamente al agente. La voz debe recuperarse como archivo, transcribirse y convertirse en texto. La imagen necesita transformarse en una URL accesible y analizarse mediante un modelo de visión antes de generar una respuesta útil.
El objetivo del workflow no es crear tres automatizaciones independientes, sino preparar tres caminos distintos que terminen convergiendo en una salida común. Esta lógica permite que el usuario reciba respuesta en el mismo chat, con independencia del formato que haya utilizado para comunicarse.
Todo flujo conversacional necesita un disparador. En este caso, el primer nodo escucha Telegram y activa el workflow cuando llega un nuevo mensaje. Su función no es transformar datos, sino entregar al resto del flujo un evento estructurado con información sobre el usuario, el chat y el contenido recibido.
La información llega en formato JSON. Dentro de esa estructura pueden aparecer campos como el identificador del chat, el identificador del usuario, el texto escrito, el archivo de voz o las distintas versiones de una imagen.
Comprender este primer JSON es esencial. Todo lo que ocurre después depende de saber localizar los campos adecuados. Si el flujo no identifica correctamente si el mensaje contiene texto, voz o imagen, las ramas posteriores no se ejecutarán como se espera.
Cuando existen más de dos posibilidades, el nodo Switch resulta especialmente útil. En lugar de preguntar simplemente si una condición se cumple o no, permite clasificar el mensaje según el tipo de contenido recibido.
El workflow puede definir una ruta para texto, otra para voz y otra para imagen. Cada regla mira un campo concreto del JSON y deja pasar solo los mensajes que contienen ese dato. Por ejemplo, la ruta de texto se activa cuando existe un mensaje escrito; la de voz, cuando aparece un identificador de archivo de audio; y la de imagen, cuando el mensaje incluye una foto.
El Switch no transforma la información. Su papel es decidir qué camino debe seguir. Por eso, las expresiones deben construirse a partir de una ejecución real y comprobar que el campo existe y no está vacío.
Un workflow robusto no solo conecta nodos; también prepara los datos para que el siguiente paso reciba exactamente lo que necesita. En el caso de un agente de IA, conviene que el mensaje llegue siempre con una estructura común.
Cuando el usuario escribe directamente, el texto ya está disponible. Cuando envía una nota de voz, primero hay que transcribirla. En ambos casos, el resultado final debe convertirse en un campo homogéneo, por ejemplo un objeto con una propiedad message.
Esta normalización evita que el agente tenga que preocuparse por el origen del contenido. Su tarea no es averiguar si el usuario escribió o habló, sino responder a una instrucción ya preparada.
Telegram no entrega directamente una nota de voz lista para transcribir. Primero proporciona un file_id, es decir, una referencia interna al archivo. El workflow debe resolver esa referencia y descargar el audio antes de enviarlo a un nodo de transcripción.
Este paso exige usar la credencial del bot y solicitar a Telegram el archivo asociado al identificador recibido. Una vez recuperado el audio como dato binario, puede pasar a un servicio de Speech to Text.
La transcripción convierte la voz en texto, y ese texto puede incorporarse a la misma lógica utilizada para los mensajes escritos. Sin este paso intermedio, el agente solo tendría una referencia al archivo, no una instrucción comprensible.
Las imágenes también requieren una preparación específica. Cuando el usuario envía una foto, Telegram puede entregar varias versiones de la misma imagen en diferentes tamaños. Habitualmente interesa seleccionar la de mayor resolución y obtener su file_id.
A partir de ese identificador, el workflow consulta Telegram para recuperar el file_path. Con esa ruta se construye una URL final que el modelo de visión pueda leer. Solo entonces la imagen puede analizarse y convertirse en una descripción, explicación o respuesta textual.
Este tratamiento es necesario porque una rama de imagen no puede pasar directamente por un agente textual. Antes debe traducirse el contenido visual a lenguaje. Además, si el usuario añade una descripción o comentario junto a la imagen, ese texto puede utilizarse como instrucción adicional para orientar el análisis.
Una vez preparada la entrada, el agente de IA se convierte en el punto central del workflow. Recibe el mensaje normalizado, aplica un prompt, utiliza un modelo de lenguaje y puede apoyarse en memoria para conservar contexto.
Conviene distinguir entre asistente y agente. Un asistente responde a una petición. Un agente, además de responder, trabaja dentro de un sistema: recibe datos preparados, sigue instrucciones, puede conservar memoria por usuario y entrega una salida compatible con el siguiente nodo.
La memoria es especialmente importante en conversaciones. Para evitar mezclar contextos, debe separarse por usuario o por chat mediante una clave de sesión estable. Así, cada persona conserva su propio historial sin interferir en la conversación de otras.
El último paso consiste en enviar la respuesta al mismo chat de Telegram. Para ello, el workflow debe recuperar el identificador del chat original y utilizarlo como destino del mensaje.
Este punto es más importante de lo que parece. Si varias ramas llegan al nodo final, todas deben entregar una respuesta compatible y conservar la información necesaria para identificar al usuario correcto. El cuerpo del mensaje puede alimentarse con la salida del agente o con la respuesta preparada desde la rama de imagen.
El cierre del flujo debe ser simple para el usuario, aunque internamente haya implicado varias rutas: escribe, habla o envía una imagen; el sistema interpreta el contenido y responde en la misma conversación.
Un flujo real con Telegram, APIs e IA debe proteger sus accesos. Las credenciales de Telegram y OpenAI deben configurarse en n8n, no pegarse como secretos visibles dentro de nodos, URLs o capturas compartidas.
También deben contemplarse errores: archivos que no se descargan, imágenes inaccesibles, campos ausentes, respuestas de IA con formatos inesperados o ramas que no devuelven el dato previsto. Un workflow mantenible no depende de que todo salga perfecto; anticipa situaciones de fallo y facilita su revisión.
En definitiva, construir un agente de Telegram con IA exige pensar menos en botones y más en lógica de flujo. Texto, voz e imagen pueden convivir en una misma automatización si cada entrada se interpreta, transforma y normaliza antes de llegar al agente.
La calidad del workflow depende de que cada nodo tenga una función clara, las credenciales estén protegidas y todas las rutas converjan en una respuesta útil para el usuario.
Este artículo es un resumen de los bloques impartidos por Miguel Ángel Rocamora, CGO en iddeass.com, en el marco del Programa Superior de IA para el Data Strategist, desarrollado por el Data Strategy Institute en la Universidad de Alicante.
En UNNIUN trabajamos para ofrecer programas formativos orientados a la toma de decisiones en entornos complejos, conectando conocimiento académico y práctica profesional.
Si quieres conocer más sobre nuestra oferta formativa o nuestras próximas actividades, puedes ponerte en contacto con nuestro equipo.